

Sélectivité d'un SELECT : quel indicateur pour estimer s'il est possible d'optimiser un ordre SQL? Selectivity of a SELECT?
Introduction
Est-ce que un client vous a déjà demandé d'optimiser un SELECT sans être sur que ce soit possible? J'entends par là qu'une requête s'exécute en 60 secondes et on vous demande de voir s'il est possible de l'exécuter en seulement 10 secondes.
Si oui, comment vous-y prenez-vous pour déterminer si cette requête est optimisable ou non? Est-ce que vous foncez tête baissée pour créer des index, faire du partitionnement, du parallélisme, du column in memory… et voir si le temps d'exécution baisse ou bien est-ce que vous utilisez, AVANT de tuner, des indicateurs, des métrics…pour décider si oui ou non on peut accélérer cette requête?
En ce qui me concerne, il me semble plus judicieux d'utiliser des indicateurs. Voici les plus connus à notre disposition mais tous ne sont pas utilisables pour notre problème :
- le ressenti utilisateur : important puisque ce sont ces utilisateurs qui viennent se plaindre, mais celui-ci n'est pas fiable car variant d'une personne à l'autre et, de plus, il ne peut pas être quantifié à part "C'est lent".
- le temps d'exécution : pas fiable car une requête complexe s'exécutant en 10 minutes peut déjà être optimisée au maximum alors qu'une requête s'exécutant en 10 secondes pourra, avec un index, s'exécuter en 0.1 seconde.
- le coût (le fameux cost) : pas fiable non plus, c'est un indicateur comme le temps d'exécution, qui en tant que tel ne permet de tirer aucune conclusion; une requête avec un coût de 200 peut-elle descendre à 10? Oui, peut-être, mais ce n'est pas en lisant ce coût qu'on peut tirer cette conclusion.
- la quantité de données récupérée : cet indicateur d'un SELECT, visible avec Autotrace, n'est d'aucune utilité. Par exemple si mon SELECT ramène 10Go de données, il est impossible de ramener ce total à 1Go (sauf en cas de déduplication des données via Oracle Net ou la compression mais c'est un autre débat). Mon SELECT ramène autant de données que nécessaire pour satisfaire le besoin utilisateur, point barre. Ajouter un index ne diminuera pas cette quantité de données à afficher à l'utilisateur.
- le débit : ah, c'est déjà plus intéressant, cette fois on a plus un seul indicateur mais une relation entre deux indicateurs. Le débit est le temps nécessaire pour traiter toutes les données de mon SELECT ramené à une unité de temps. Par exemple un SELECT qui ramène 10Go en 30 secondes a un excellent débit mais cela ne me dit pas si je peux optimiser ce SELECT ou non.
Sur les deux derniers exemples (quantité de données et débit), on approche d'un indicateur très intéressant, qui est le nombre de blocs lus par ligne d'un SELECT. Imaginons que mon SELECT ramène 10 lignes mais que pour cela Oracle ait été obligé de lire 100 000 blocs de 8Ko : tout de suite vous sentez que ce n'est pas bon et qu'une optimisation est possible : 100 000 blocs pour une ligne soit 800Mo de données. En revanche si pour afficher ces 10 lignes, Oracle a du lire 1 bloc et un seul : pas d'optimisation possible, on ne peut pas descendre à 0 :-)
ATTENTION cependant à la taille des infos ramenées par la requête. Un SELECT * sur une table avec des LOB ou 1000 colonnes VARCHAR2 de 33000 octets remplies au max va devoir lire bien plus de blocs que un SELECT * sur une table de 10 colonnes de type number; mais je parlerai dans cet article que d'un cas général : 30, 50 colonnes, pas de LOB, des VARCHAR2 ou CHAR ne dépassant pas les 100 caractères… une table basique quoi.
Le calcul de cet indicateur que j'appelle "sélectivité du Select" est : NB buffers / NB rows.
C'est donc cet indicateur que je vais étudier dans cet article, voir s'il est vraiment fiable, quelles sont ses limites etc etc .
Pour info, Christian Antognini, DBA Oracle depuis 1995, qui a écrit l'excellent livre " Troubleshooting Oracle Performance" en 2014, précise page 450 que pour identifier les plans d’exécution suboptimal, il faut se baser sur « the number of logical reads (the number of blocks that are accessed in the buffer cache during the execution of a SQL statement) ». Il donne même des valeurs limites pour identifier si un plan peut être optimisé ou non : on remarque qu'il manque les parties entre 5 et 10 logicals reads et entre 15 et 20 …
• Access paths that lead to less than about 5 logical reads per returned row are probably good
• Access paths that lead to up to about 10–15 logical reads per returned row are probably acceptable
• Access paths that lead to more than about 20 logical reads per returned row are probably inefficient. In other words, there is probably room for improvement
Son livre : https://www.amazon.fr/Troubleshooting-Oracle-Performance-Christian-Antognini/dp/143025758X
Si j'ai appelé cet indicateur "sélectivité du Select" c'est parce que, avec cet indicateur, on a un équivalent de la sélectivité d'une colonne mais pour l'ordre SQL entier! La sélectivité c'est le pourcentage d'une valeur sur une colonne. Par exemple j'ai une table de 1 000 rows, une colonne VIP avec deux valeurs, la valeur 1 est présente 1 fois, la valeur 2 est présente 999 fois. La sélectivité de 1 est de 1/1000 = 0,1% et celle de 2 est de 999/1000 = 99,9%. Dis comme cela c'est simple, il est facile de comprendre que sur la colonne VIP il faut un index si on fait des recherches avec WHERE VIP=1 pout éviter le full table scan. MAIS quid d'une requête qui fait 50, 100 voir 200 lignes avec 20 jointures, 10 sous-requêtes, 20 prédicat de recherche? NE RIEZ PAS, cela existe (et parfois c'est même bien plus complexe) et ça donne des sueurs froides… Il est impossible dans ce cas de rapidement calculer la sélectivité des sous-requêtes, des clauses WHERE… puis celle de l'ordre SQL entier, donc, en utilisant cet indicateur, on aura une sélectivité calculée par Oracle portant carrément sur tout l'ordre SQL :-) Elle est pas belle la vie? C'est Oracle qui bosse pour nous!
On trouve cet indicateur dans le livre de Antognini mais aussi dans le Cloud Control, preuve de plus qu'il est vraiment pertinent.
Allez dans le menu Performance / Top Activity, Partie Top SQL : clic droit sur SQL Id pour ouvrir l’écran Détail de cet ordre SQL dans un nouvel écran. ATTENTION, je crois que le contenu de cet onglet change selon que l'on est en mode temps réel ou que l'on est en mode Historique (quand on regarde le contenu d'un snapshot AWR donc des ordres SQL datant d'avant le dernier snapshot AWR pris).
Dans l'écran ci-dessous, c'est le bloc entouré de rouge à droite, en bas, qui est intéressant.
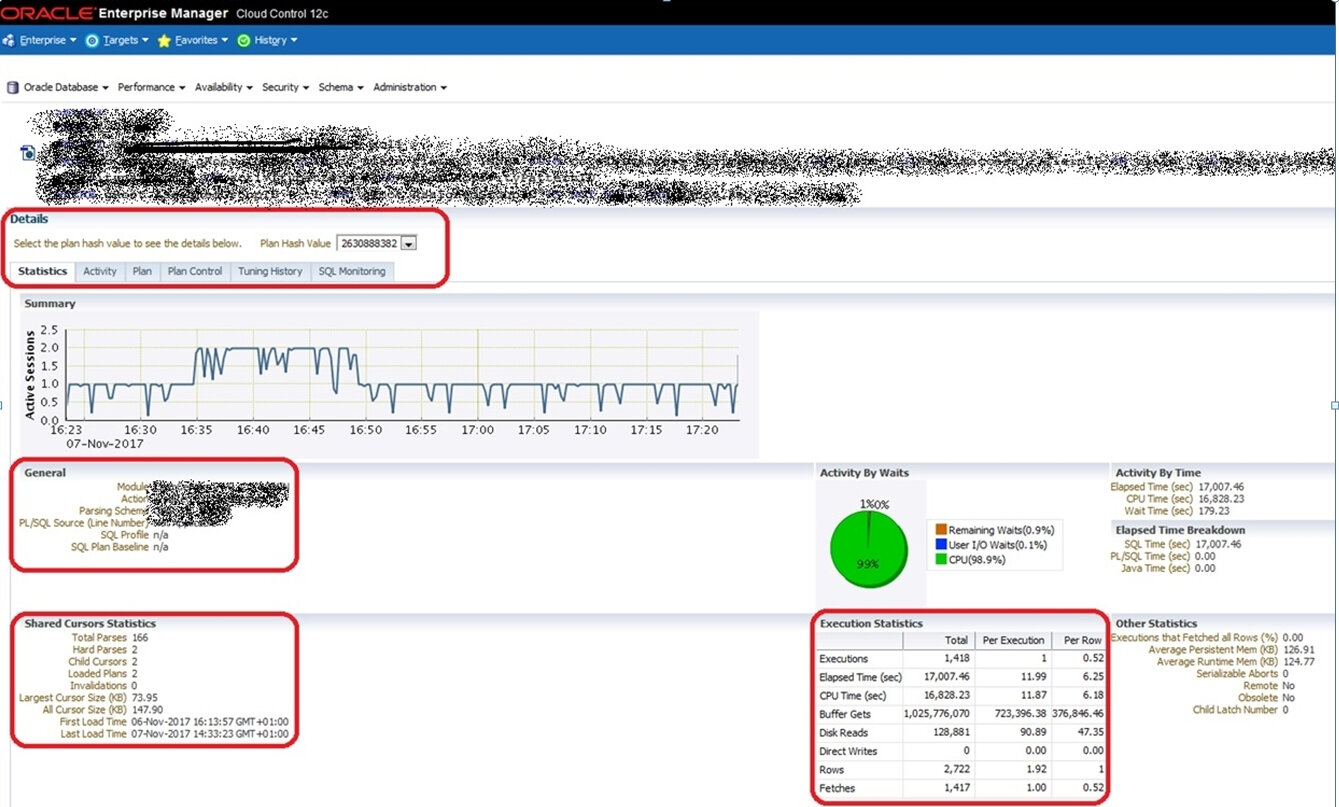
Voici le grossissement : la dernière colonne est bien "Per row" donc on a la liste des indicateurs du Select ramené à une ligne.
Ce Select ramène 2 722 lignes pour 1418 exécutions, soit 1,92 lignes à chaque fois. Il lit 1 025 776 070 buffers pour 1 418 exécutions, ce qui fait 723 396 buffers par exécution et 376 846 buffers par ligne : là c'est clair qu'il faut optimiser!
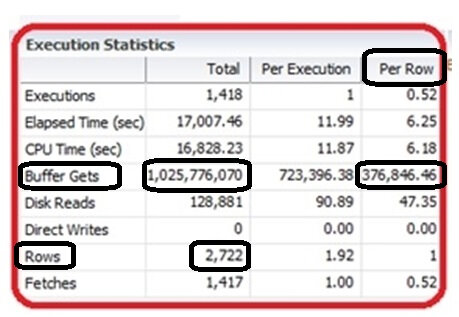
Dans un autre document trouvé sur le net, un DBA présentait lui aussi cet indicateur via un rapport AWR : vous êtes convaincus maintenant de son utilité?
Ah, dernière chose, le plus simple pour savoir si on peut optimiser un ordre SQL est de lancer le SQL Tuning Advisor et le SQL Access Advisor mais tous les clients n'ont pas le Tuning Pack ... alors il est bon de connaître une méthode manuelle :-)
Alors bien sur il y a des cas où ça marche moins bien mais cet indicateur est vraiment puissant, il faut savoir qu'il existe.
Pour mes tests j'utilise des ordres SQL très simples pour des raisons de facilité de mise en peuvre mais cette méthode marche surtout pour les ordres très complexes.
Points d'attention
N/A.
Base de tests
Une base Oracle 18c.
Exemples
============================================================================================
L'environnement de recette
============================================================================================
On utilise une table de 1 million d'enregistrements.
SQL> CREATE TABLE zztest AS SELECT * FROM dba_objects WHERE rownum < 20001;
Table created.
SQL> INSERT INTO zztest SELECT * FROM zztest;
20000 rows created.
SQL> /
40000 rows created.
...
SQL> /
640000 rows created.
SQL> commit;
SQL> select count(*) from zztest;
COUNT(*)
----------
1280000
Ajout d'un identifiant.
SQL> ALTER TABLE zztest ADD id number;
SQL> UPDATE zztest SET id = rownum;
1280000 rows updated.
SQL> commit;
Ajout d'un index et génération des stats.
SQL> ALTER TABLE zztest ADD CONSTRAINT pk_zztest PRIMARY KEY (id);
SQL> exec DBMS_STATS.GATHER_TABLE_STATS (ownname => 'HR' , tabname => 'ZZTEST', cascade => true);
La table occupe 24 000 blocs et l'index 2 800.
SQL> select segment_name, blocks from dba_segments where segment_name in ( 'ZZTEST', 'PK_ZZTEST');
SEGMENT_NAME BLOCKS
----------------------------------------
ZZTEST 23552
PK_ZZTEST 2816
============================================================================================
SELECTs avec ROWIDs
============================================================================================
On utilise le hint gather_plan_statistics pour avoir la colonne Buffers dans le plan d'exécution.
ROWID - SELECT D'UNE LIGNE
Résultat : 1 buffer par ligne.
Voilà la façon la plus rapide d'accéder à une donnée sous Oracle : utiliser son ROWID (c'était même la première règle du RBO).
SQL> select rowid from zztest where rownum = 1;
ROWID
------------------
AAAUKFAAMAAACRDAAA
SQL> select /*+ gather_plan_statistics */ * from zztest where rowid = 'AAAUKFAAMAAACRDAAA';
OWNER OBJECT_NAME SUBOBJECT_NAME OBJECT_ID DATA_OBJECT_ID OBJECT_TYPE CREATED LAST_DDL_ TIMESTAMP STATUS T G S NAMESPACE EDITION_NAME SHARING E O A DEFAULT_COLLATION D S CREATED_APPID CREATED_VSNID MODIFIED_APPID MODIFIED_VSNID ID
----------------------------------------------------------------------------------------------------------- ----------------------------------------------------------------------
SYS I_FILE#_BLOCK# 9 9 INDEX 26-JAN-17 26-JAN-17 2017-01-26:13:52:53 VALID N N N 4 NONE Y N N N
Et que voit-on? Oracle n'a eu à lire qu'un seul buffer pour ramener une ligne :-)
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------
SQL_ID 1kwbmj9ubvzma, child number 0
-------------------------------------
select /*+ gather_plan_statistics */ * from zztest where rowid ='AAAUKFAAMAAACRDAAA'
Plan hash value: 833697196
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 1 |
| 1 | TABLE ACCESS BY USER ROWID| ZZTEST | 1 | 1 | 1 |00:00:00.01 | 1 |
-----------------------------------------------------------------------------------------------
ROWID - SELECT DES DIX PREMIERES LIGNES DANS LE MÊME BLOC
Résultat : 2 buffers de lus soit 2/10 = 0.2 buffer par ligne.
Mais attention, on a un super Clustering Factor donc le test n'est pas hyper pertinent mais il montre bien que le nombre de buffers lus augmente avec le nombre de lignes ramenées, même si c'est le même bloc.
SQL> select rowid from zztest where rownum < 11;
ROWID
------------------
AAAUKFAAMAAACRDAAA
AAAUKFAAMAAACRDAAB
AAAUKFAAMAAACRDAAC
AAAUKFAAMAAACRDAAD
AAAUKFAAMAAACRDAAE
AAAUKFAAMAAACRDAAF
AAAUKFAAMAAACRDAAG
AAAUKFAAMAAACRDAAH
AAAUKFAAMAAACRDAAI
AAAUKFAAMAAACRDAAJ
SQL> select /*+ gather_plan_statistics */ * from zztest where rowid IN ('AAAUKFAAMAAACRDAAA','AAAUKFAAMAAACRDAAB','AAAUKFAAMAAACRDAAC','AAAUKFAAMAAACRDAAD','AAAUKFAAMAAACRDAAE','AAAUKFAAMAAACRDAAF','AAAUKFAAM AAACRDAAG','AAAUKFAAMAAACRDAAH','AAAUKFAAMAAACRDAAI','AAAUKFAAMAAACRDAAJ');
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID f963u8zq3nbbh, child number 1
-------------------------------------
select /*+ gather_plan_statistics */ * from zztest where rowid IN
('AAAUKFAAMAAACRDAAA','AAAUKFAAMAAACRDAAB','AAAUKFAAMAAACRDAAC','AAAUKFAAMAAACRDAAD','AAAUKFAAMAAACRDAAE','AAAUKFAAMAAACRDAAF','AAAUKFAAM AAACRDAAG','AAAUKFAAMAAACRDAAH','AAAUKFAAMAAACRDAAI','AAAUKFAAMAAACRDAAJ')
Plan hash value: 904234787
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 10 |00:00:00.01 | 2 |
| 1 | INLIST ITERATOR | | 1 | | 10 |00:00:00.01 | 2 |
| 2 | TABLE ACCESS BY USER ROWID| ZZTEST | 10 | 1 | 10 |00:00:00.01 | 2 |
------------------------------------------------------------------------------------------------
Note
-----
- statistics feedback used for this statement
21 rows selected.
Le premier enregistrement (ROWID N°1) est dans le bloc 9283, ainsi que le dixième.
Cela montre que même si Oracle lit un seul data bloc, la colonne BUFFERS est actualisée deux fois.
SQL> DECLARE
ridtyp NUMBER;
objnum NUMBER;
relfno NUMBER;
blno NUMBER;
rowno NUMBER;
rid ROWID;
BEGIN
select rowid into RID from zztest where rowid = 'AAAUKFAAMAAACRDAAA';
dbms_rowid.rowid_info(rid,ridtyp,objnum,relfno,blno,rowno,'SMALLFILE');
dbms_output.put_line('Block No-' || TO_CHAR(blno));
END;
/
Block No-9283
SQL> DECLARE
ridtyp NUMBER;
objnum NUMBER;
relfno NUMBER;
blno NUMBER;
rowno NUMBER;
rid ROWID;
BEGIN
select rowid into RID from zztest where rowid = 'AAAUKFAAMAAACRDAAJ';
dbms_rowid.rowid_info(rid,ridtyp,objnum,relfno,blno,rowno,'SMALLFILE');
dbms_output.put_line('Block No-' || TO_CHAR(blno));
END;
/
Block No-9283
ROWID - SELECT DE DIX LIGNES DANS DES BLOCS DIFFERENTS
Résultat : 10 buffers de lus pour 10 lignes = 1 buffer par ligne.
SQL> SQL> select * from (select rownum AS "R", rowid AS "ROW" from zztest order by rownum) SUB where SUB.R IN (1, 10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000);
R ROW
---------- ------------------
1 AAAUKFAAMAAACRDAAA
10000 AAAUKFAAMAAACU5AAG
20000 AAAUKFAAMAAACXuAAp
30000 AAAUKFAAMAAACagAAa
40000 AAAUKFAAMAAACdQAAu
50000 AAAUKFAAMAAACgEAAd
60000 AAAUKFAAMAAACi3AAu
70000 AAAUKFAAMAAAClpAAp
80000 AAAUKFAAMAAACodAAp
90000 AAAUKFAAMAAACrOAAH
10 rows selected.
SQL> DECLARE
ridtyp NUMBER;
objnum NUMBER;
relfno NUMBER;
blno NUMBER;
rowno NUMBER;
rid ROWID;
BEGIN
SQL> select rowid into RID from zztest where rowid ='AAAUKFAAMAAACrOAAH';
dbms_rowid.rowid_info(rid,ridtyp,objnum,relfno,blno,rowno,'SMALLFILE');
dbms_output.put_line('Block No-' || TO_CHAR(blno));
END;
/
AAAUKFAAMAAACRDAAA : Block No-9283
AAAUKFAAMAAACU5AAG : Block No-9529
AAAUKFAAMAAACXuAAp : Block No-9710
AAAUKFAAMAAACagAAa : Block No-9888
AAAUKFAAMAAACdQAAu : Block No-10064
AAAUKFAAMAAACgEAAd : Block No-10244
AAAUKFAAMAAACi3AAu : Block No-10423
AAAUKFAAMAAAClpAAp : Block No-10601
AAAUKFAAMAAACodAAp : Block No-10781
AAAUKFAAMAAACrOAAH : Block No-10958
SQL> select /*+ gather_plan_statistics */ * from zztest where rowid IN ('AAAUKFAAMAAACRDAAA','AAAUKFAAMAAACU5AAG','AAAUKFAAMAAACXuAAp','AAAUKFAAMAAACagAAa','AAAUKFAAMAAACdQAAu','AAAUKFAAMAAACgEAAd','AAAUKFAAM AAACi3AAu','AAAUKFAAMAAAClpAAp','AAAUKFAAMAAACodAAp','AAAUKFAAMAAACrOAAH');
...
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
---------------------------------------------------------
SQL_ID 61a8nzgxwugjh, child number 0
-------------------------------------
select /*+ gather_plan_statistics */ * from zztest where rowid IN
('AAAUKFAAMAAACRDAAA','AAAUKFAAMAAACU5AAG','AAAUKFAAMAAACXuAAp','AAAUKFAAMAAACagAAa','AAAUKFAAMAAACdQAAu','AAAUKFAAMAAACgEAAd','AAAUKFAAM AAACi3AAu','AAAUKFAAMAAAClpAAp','AAAUKFAAMAAACodAAp','AAAUKFAAMAAACrOAAH')
Plan hash value: 904234787
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 10 |00:00:00.01 | 10 |
| 1 | INLIST ITERATOR | | 1 | | 10 |00:00:00.01 | 10 |
| 2 | TABLE ACCESS BY USER ROWID| ZZTEST | 10 | 1 | 10 |00:00:00.01 | 10 |
------------------------------------------------------------------------------------------------
17 rows selected.
============================================================================================
SELECT avec INDEX
============================================================================================
INDEX - SELECT DE UNE LIGNE
Résultat : 4 buffers par ligne; 3 pour parcourir l'index, un pour faire le SELECT = 4 buffers par ligne.
SELECT avec utilisation d'un index par le CBO : 4 buffers lus car Oracle doit parcourir l'index, visiblement il y a trois blocs de la racine à la feuille, pour récupérer le rowid et lire le bloc de la table.
SQL> select /*+ gather_plan_statistics */ * from zztest where id = 1;
…
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------
SQL_ID dhcapcnf21y3r, child number 0
-------------------------------------
select /*+ gather_plan_statistics */ * from zztest where id = 1
Plan hash value: 2630418637
---------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.05 | 4 | 1 |
| 1 | TABLE ACCESS BY INDEX ROWID| ZZTEST | 1 | 1 | 1 |00:00:00.05 | 4 | 1 |
|* 2 | INDEX UNIQUE SCAN | PK_ZZTEST | 1 | 1 | 1 |00:00:00.05 | 3 | 1 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"=1)
19 rows selected.
INDEX - SELECT DE DIX LIGNES
Résultat : 6 buffers de lus pour dix lignes = 0,6 buffer par ligne.
SQL> select /*+ gather_plan_statistics */ * from zztest where id < 11;
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------
SQL_ID ckz8jrq3ds4p2, child number 0
-------------------------------------
select /*+ gather_plan_statistics */ * from zztest where id < 11
Plan hash value: 508690300
---------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 10 |00:00:00.01 | 6 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| ZZTEST | 1 | 10 | 10 |00:00:00.01 | 6 |
|* 2 | INDEX RANGE SCAN | PK_ZZTEST | 1 | 10 | 10 |00:00:00.01 | 4 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"<11)
19 rows selected.
INDEX - SELECT DE TOUTE LA TABLE AVEC UN INDEX
Résultat : 194 000 buffers pour 1 280 000 lignes = 0.15 buffer par ligne.
SQL> select /*+ gather_plan_statistics INDEX(zztest pk_zztest) */ * from zztest;
…
1280000 rows selected.
Elapsed: 00:02:02.92
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------
SQL_ID 8c6rbrfwmh6j1, child number 0
-------------------------------------
select /*+ gather_plan_statistics INDEX(zztest pk_zztest) */ * from zztest
Plan hash value: 3499362218
-----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1280K|00:00:02.35 | 194K|
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| ZZTEST | 1 | 1280K| 1280K|00:00:02.35 | 194K|
| 2 | INDEX FULL SCAN | PK_ZZTEST | 1 | 1280K| 1280K|00:00:01.06 | 87867 |
-----------------------------------------------------------------------------------------------------------
15 rows selected.
============================================================================================
SELECT avec Full Table Scan
============================================================================================
FULL TABLE SCAN - SELECT DE UNE LIGNE
Résultat : 22 621 buffers pour une ligne.
Même recherche mais avec un Full Table Scan via un hint : 22621 buffers lus… (presque le nombre complet de blocs occupés par la table).
SQL> select /*+ gather_plan_statistics FULL(zztest) TEST INDICATEUR */ * from zztest where id = 1;
…
Elapsed: 00:00:00.15
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID f224rj86ydphm, child number 0
-------------------------------------
select /*+ gather_plan_statistics FULL(zztest) TEST INDICATEUR */ * from zztest where id = 1
Plan hash value: 3582063246
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.02 | 22621 | 22600 |
|* 1 | TABLE ACCESS FULL| ZZTEST | 1 | 1 | 1 |00:00:00.02 | 22621 | 22600 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=1)
19 rows selected.
FULL TABLE SCAN - SELECT DE DIX LIGNES
Résultat : 22 62 buffers par ligne.
SQL> select /*+ gather_plan_statistics FULL(zztest) TEST INDICATEUR */ * from zztest where id < 11;
...
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID 8bda1tqt8qd7j, child number 0
-------------------------------------
select /*+ gather_plan_statistics FULL(zztest) TEST INDICATEUR */ * from zztest where id < 11
Plan hash value: 3582063246
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 10 |00:00:00.01 | 22621 | 22593 |
|* 1 | TABLE ACCESS FULL| ZZTEST | 1 | 10 | 10 |00:00:00.01 | 22621 | 22593 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"<11)
19 rows selected.
FULL TABLE SCAN - SELECT DE TOUTES LES LIGNES
Résultat : 0.08 buffer par ligne.
SQL> select /*+ gather_plan_statistics TEST INDICATEUR */ * from zztest;
...
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------
SQL_ID 04c6hxpg2vcrf, child number 0
-------------------------------------
select /*+ gather_plan_statistics TEST INDICATEUR */ * from zztest
Plan hash value: 3582063246
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1280K|00:00:01.01 | 106K| 724 |
| 1 | TABLE ACCESS FULL| ZZTEST | 1 | 1280K| 1280K|00:00:01.01 | 106K| 724 |
-----------------------------------------------------------------------------------------------
13 rows selected.
============================================================================================
SELECT sur une colonne non indexée
============================================================================================
Maintenant prenons le cas d'une colonne non indexée et qui ne soit pas un ID.
Voyons la répartition des valeurs de la colonne OBJECT_TYPE dans la table de test.
SQL> select OBJECT_TYPE, count(*) from zztest group by object_type order by 2;
OBJECT_TYPE COUNT(*)
----------------------- ----------
EDITION 64
RULE 64
...
SYNONYM 359296
VIEW 400320
38 rows selected.
FULL TABLE SCAN - SELECT DE 64 LIGNES
Et si on recherche sur le type d'objet le plus rare? On a 22 617 buffers pour 64 rows soit 353.40 ==>x IL FAUT UN INDEX pour cette recherche!
SQL> select /*+ gather_plan_statistics */ * from zztest where object_type = 'EDITION';
…
64 rows selected.
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
-------------------------------------
SQL_ID 011vu2g8hqy2v, child number 0
-------------------------------------
select /*+ gather_plan_statistics */ * from zztest where object_type = 'EDITION'
Plan hash value: 3582063246
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 64 |00:00:00.01 | 22617 | 1594 |
|* 1 | TABLE ACCESS FULL| ZZTEST | 1 | 33684 | 64 |00:00:00.01 | 22617 | 1594 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_TYPE"='EDITION')
19 rows selected.
FULL TABLE SCAN - SELECT DE 400 320 LIGNES
Et pour une recherche sur le type d'objet le plus fréquent? On a 48 801 buffers pour 400 320 rows soit 0.12 donc pas besoin d'index dans ce cas.
SQL> select /*+ gather_plan_statistics */ * from zztest where object_type = 'VIEW';
…
400320 rows selected.
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last'));
PLAN_TABLE_OUTPUT
-------------------------------------
SQL_ID 57v06f7f19u1r, child number 0
-------------------------------------
select /*+ gather_plan_statistics */ * from zztest where object_type ='VIEW'
Plan hash value: 3582063246
--------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 400K|00:00:00.56 | 48801 |
|* 1 | TABLE ACCESS FULL| ZZTEST | 1 | 400K| 400K|00:00:00.56 | 48801 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_TYPE"='VIEW')
19 rows selected.
============================================================================================
Résumé des tests
============================================================================================
ROWID
Pas d'optimisation nécessaire, car ce mode d'accès aux données est le plus rapide sous Oracle.
1 - Select via rowid de 1 enregistrement : 1 buffer lu soit 1/1 = 1 buffer lu par ligne
2 - Select via rowid de 10 enregistrements stockés dans le même bloc : 2 buffers lus soit 2/10 = 0.2 buffer par ligne
3 - Select via rowid de 10 enregistrements stockés dans dix blocs différents : 10 buffers lus soit 10/10 = 1 buffer par ligne
Test Nb lignes Nb buffers Sélectivité SELECT Règle respectée CONCLUSION
1 1 1 1 OK Pas d'optimisation nécessaire
2 10 2 0.2 OK Pas d'optimisation nécessaire
3 10 10 1 OK Pas d'optimisation nécessaire
INDEX
Index : Attention, si on utilise un index pour récupérer un enregistrement, on ne peut pas descendre en dessous d'un nombre qui est "Nb de blocs dans l'index pour aller de la racine à la feuille" + "un bloc de la table". Donc n'attendez pas à avoir des chiffres pour la sélectivité aussi bons que ceux par accès par Rowid ou, dans certains cas, par Full Table Scan.
4 - Select via index de 1 enregistrement : 4 buffers lus (3 pour parcourir l'index, un pour accéder à la table) soit 4/1 = 4 buffers par ligne
5 - Select via index de 10 enregistrements : 6 buffers lus soit 6/10 = 0.6 buffer par ligne
6 - Select via index de 1 280 000 enregistrements : 194 000 buffers lus soit 194000/1280000 = 0.15 buffer par ligne
Test Nb lignes Nb buffers Sélectivité SELECT Règle respectée CONCLUSION
4 1 4 4 OK Pas d'optimisation nécessaire
5 10 6 0.6 OK Pas d'optimisation nécessaire
6 1280 000 194 000 0.15 KO Le résultat est étrange en apparence. La sélectivité du SELECT est excellente MAIS on aura lu TOUS les blocs de la table plus TOUS les blocs de l'index… Un Full Table Scan sera plus performant, surtout que Oracle fait du Multi Blocs Read (MBR) alors qu'une lecture par index fait de la lecture mono bloc. Néanmoins, même si je n'ai pas affiché ici le temps d'exécution de la requête, la différence entre les deux n'était pas extraordinaire, à cause de la quantité de données manipulée.
FULL TABLE SCAN
7 - Select via full table scan de 1 enregistrement : 22 621 buffers lus soit 22621/1 = 22 621 buffers par ligne
8 - Select via full table scan de 10 enregistrements : 22 621 buffers lus soit 22621/10 = 2262 buffers par ligne
9 - Select via full table scan de 1 280 000 enregistrements : 106 000 buffers lus soit 106000/1280000 = 0.08 buffer par ligne
Test Nb lignes Nb buffers Sélectivité SELECT Règle respectée CONCLUSION
7 1 22 621 22 621 OK Remplacer le FTS par un index
8 10 22 621 2 262 OK Remplacer le FTS par un index
9 1280 000 106 000 0.08 OK Pas d'optimisation nécessaire
FULL TABLE SCAN D'UNE COLONNE NON INDEXEE
10 - Select via full table scan de 64 enregistrements : 22617 buffers lus soit 22617/64 = 353.4 buffers par ligne
11 - Select via full table scan de 400 320 enregistrements : 48 801 buffers lus soit 48801/400320 = 0.12 buffer par ligne
Test Nb lignes Nb buffers Sélectivité SELECT Règle respectée CONCLUSION
10 64 22 617 353.4 OK Remplacer le FTS par un index
11 400 320 48 801 0.12 OK Pas d'optimisation nécessaire
============================================================================================
Conclusion
============================================================================================
Avec les tests effectués, on peut conclure que cet indicateur est excellent, il permet de dire si oui ou non un SELECT est optimisable ou non, sans passer par un Advisor.



/https%3A%2F%2Fassets.over-blog.com%2Ft%2Fcedistic%2Fcamera.png)
/https%3A%2F%2Fprofilepics.canalblog.com%2Fprofilepics%2F1%2F5%2F1555182.jpg)